AI社会の実現に向けた、IOWN APNによるGPUの3拠点分散データセンター構築を世界で初めて成功
ドコモグループの法人事業ブランド「ドコモビジネス」を展開するNTTコミュニケーションズ株式会社(以下 NTT Com)は、超高速かつ超低消費電力を実現するIOWN構想※1の主要技術であるオールフォトニクス・ネットワーク※2(以下 APN)で接続した3拠点のデータセンターにNVIDIA H100 GPUサーバーを分散配置した環境で、NVIDIA AI Enterpriseソフトウェア プラットフォームの一部であるNVIDIA NeMo(TM)※3を用いたNTT版大規模言語モデル tsuzumi ※4の学習実証実験(以下 本実証)に世界で初めて成功しました。
1.背景
生成AIやデータ利活用の進展に伴い、GPUクラスタの重要性が増しています。しかし、単一のデータセンターでは、生成AIのモデルサイズ増大による処理量の変動やリソース確保の制約、データセンターごとのキャパシティや電力供給の制限に応じた運用が求められるなど、さまざまな課題が存在します。
NTT Comではこの課題に対して、三鷹と秋葉原の2拠点のデータセンター間でAPNによるGPUクラスタの実効性を検証し、その効果性を確認してきました。2拠点から3拠点、さらには多数のデータセンターへと分散を進めることで、余ったGPUサーバーを再利用するような最適なGPUリソースの配置がより実用的になります。また各地域のデータセンターを活用し、複数の拠点でコンピューティングを分散することで、電力コスト削減と持続可能な運用を実現します。
2.本実証の概要
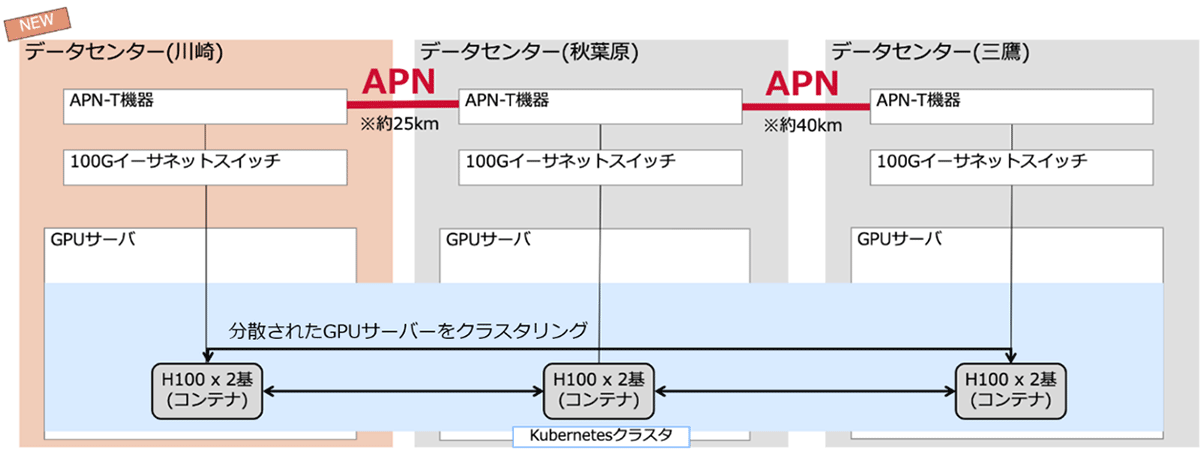
本実証では、Point-to-Pointで接続された分散データセンターの数を2拠点から、川崎を加えた3拠点へと拡張しました。これにより、計算基盤の運用に新たな柔軟性が生まれます。例えば、A拠点・B拠点に加え、C拠点を活用することで、その土地の電力供給量や値段に応じ、お客さまの要望に合わせた複数の運用パターンを選択できるようになります。またネットワークの観点からも、距離の近い拠点同士でのより低遅延なワークロードや、遠距離の拠点同士での電力効率を意識したワークロードなど、ユーザーの特性に応じた分散学習や推論などのスケジューリングの可能性を実感できる構成となります。
本実証では、NVIDIA アクセラレーテッドサーバーをそれぞれ約25~50km離れた川崎と三鷹と秋葉原の3拠点のデータセンターに分散配置し、データセンター間を100Gbps回線のIOWN APNで接続しました。NVIDIA NeMo(TM) を使用して、3拠点のGPUサーバーを連携させ、tsuzumiモデル 7B ※5の分散学習を実施しました。
本実証で用いた技術の主な特長は以下の通りです。
(1) IOWN APN
IOWN APNの高速・低遅延接続により、GPUサーバー間のデータ転送が迅速かつ効率的に行われ、小規模なAIモデルの事前学習や追加学習などの比較的軽量な処理に対して、単一のデータセンターと遜色ない性能を発揮できます。これによって、複数のデータセンター環境で柔軟にGPUクラスタを構築し、効率的なリソース利用を実現することが可能です。
(2) NVIDIA NeMo(TM)
分散学習に対応した大規模言語モデルの学習、カスタマイズ、展開のためのエンド ツー エンド プラットフォームであるNVIDIA NeMo(TM)を活用しました。将来的にさまざまな生成AIの処理に対応可能です。
(3)Kubernetes※6
複数のノードにモデルのトレーニングを分散させることで、大規模データに対する計算効率を向上させます。コンテナを用いた柔軟なスケーリングが可能であり、リソース管理やフォールトトレランス※7にも優れています。またイーサネットと組み合わせ、セキュリティとネットワークの分離を実現するマルチテナントの実現も可能です。
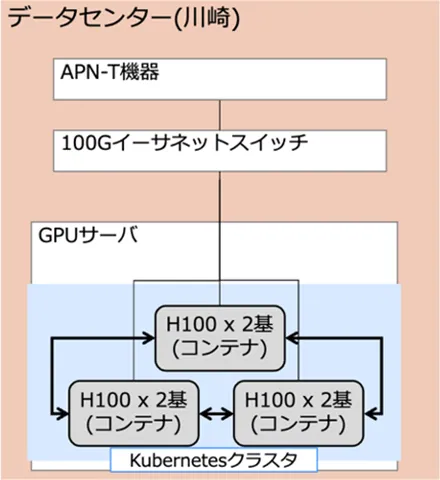
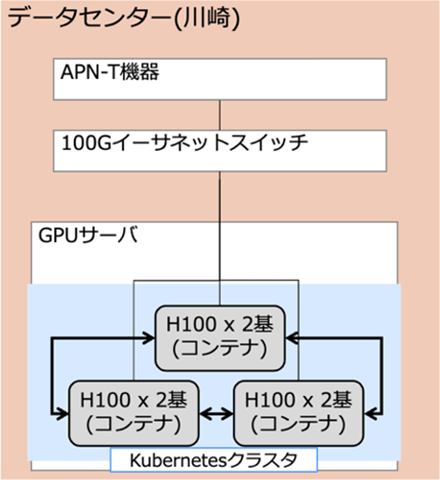
<1拠点での実証のイメージ>
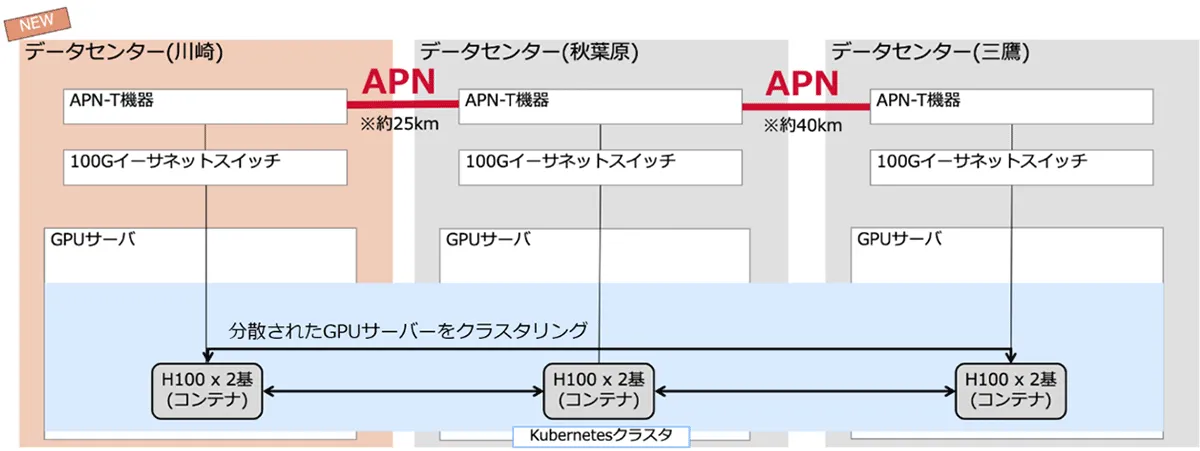
<3拠点での実証のイメージ>
3.本実証の成果
本実証は世界で初めて、3拠点のデータセンターをIOWN APNで繋ぎ、NVIDIA NeMo(TM)を組み合わせた環境で、生成AIのモデル学習(tsuzumi 7Bの事前学習※8)を動作させることに成功しました。
単一のデータセンターで学習させる場合の所要時間と比較して、インターネットを想定し帯域制限を実施したTCP通信の分散データセンターでは9.187倍の時間を要しましたが、IOWN APN経由の分散データセンターでは1.105倍と、単一のデータセンターとほぼ同等の性能を発揮できることを確認しました。
4.今後の展開
本実証に引き続き、社会産業を支えるデジタルインフラをめざし、以下2つの観点から実証を進めてまいります。
(1)日本全国での分散データセンターの配置を見越した、拠点数の増加と距離延伸の実証
(2)APNで接続された分散データセンターにおける通信方法やGPUリソースの最適化検証※9 (特許出願中)
また本実証の成果をもとに、IOWN APNで接続された分散データセンターにおけるGPUクラスタの可能性をさらに広げ、国内70拠点以上のデータセンター間やお客さまビルなどを接続可能な「APN専用線プラン powered by IOWN」や、液冷方式サーバーに対応した超省エネ型データセンターサービス「Green Nexcenter(R)」などを組み合せたGPUクラウドソリューションとしてお客さまへ提供をめざします。
5.GTC 2025 「Japan AI Day」セッション情報
2025年3月21日(金)10時よりGTC(GPU Technology Conference) 2025の一環としてオンライン限定で開催される「Japan AI Day」にて、本実証の元となる技術詳細や情報を出展予定です。セッション情報よりご確認ください。
■セッション名:大規模言語モデル学習スケールのためのテレコムユースケース
■登壇者名:露崎 浩太、鈴ヶ嶺 聡哲
■参加方法:GTCの公式サイトよりご確認ください。https://www.nvidia.com/ja-jp/gtc/
■セッション情報:こちらよりご確認ください。
※1:IOWN (Innovative Optical and Wireless Network)構想とは、NTTが提唱する次世代情報通信基盤です。
https://group.ntt/jp/group/iown/ 「IOWN(R)」は、日本電信電話株式会社の商標又は登録商標です。
※2:オールフォトニクス・ネットワーク(APN)とは、IOWNを構成する主要な技術分野の1つとして、端末からネットワークまで、すべてにフォトニクス(光)ベースの技術を導入し、エンド・ツー・エンドでの光波長パスを提供する波長ネットワークにより、圧倒的な低消費電力、高速大容量、低遅延伝送の実現をめざすものです。
※3:NVIDIA NeMo(TM) とは、生成AIモデルを構築・カスタマイズ・デプロイするための開発プラットフォームです。https://docs.nvidia.com/nemo-framework/index.html
※4:tsuzumi:「tsuzumi」は軽量でありながら世界トップレベルの日本語処理性能を持つ大規模言語モデルです。「tsuzumi」のパラメタサイズは6~70億と軽量であるため、市中のクラウド提供型LLMの課題である学習やチューニングに必要となるコストを低減します。
※5:tsuzumiモデル 7B とは、tsuzumiのモデルで、パラメータ数が70億のものです。
※6:Kubernetesとは、コンテナ化したアプリケーションを管理するためのオープンソースのオーケストレーションシステムです。
※7:フォールトトレランスとは、システムや機器などの一部が故障・停止しても、その機能を保ち、正常に稼働させ続ける仕組みです。
※8:事前学習(Pre-training)とは、大規模なデータセットを使用してモデルに基本的な知識を習得させるプロセスのことです。
※9:APNに関連する技術において特許出願中となります。
【関連リンク】
ニュース 2024年10月7日:NTT Com、IOWN APNを活用した分散データセンターでの生成AI学習実証実験に世界で初めて成功|ドコモビジネス|NTTコミュニケーションズ 企業情報
https://www.ntt.com/about-us/press-releases/news/article/2024/1007.html